Myself and several other Microsoft Engineers were recently struggling with intermittent AKS node issues. When the issue occurred, the node(s) would not allow new pods to be created, or any method of connecting a terminal session. In short, there was no method of collecting logs from these broken nodes.
Solution
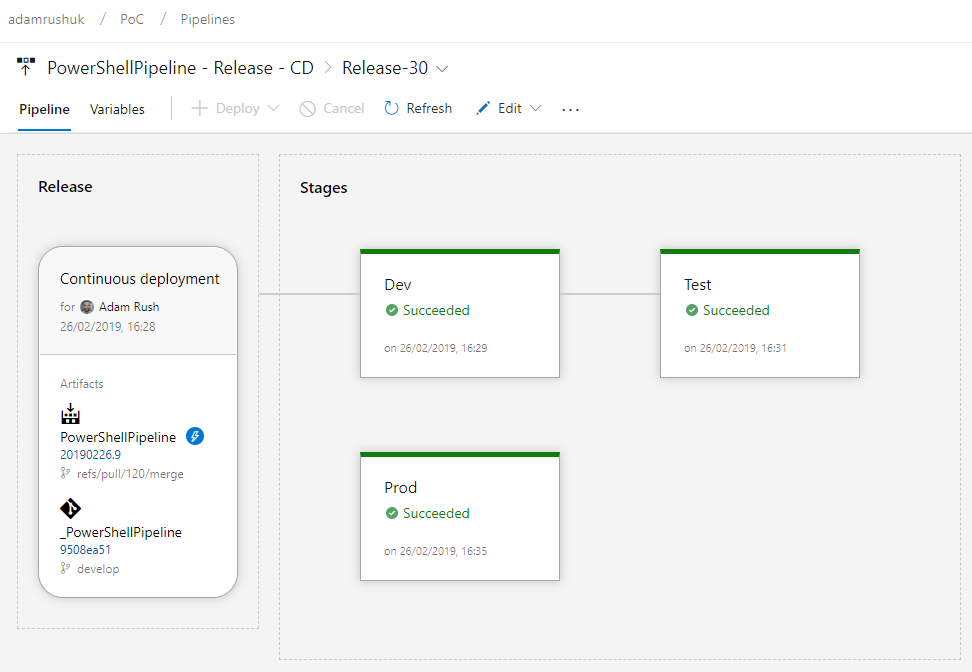
The solution for log collection was to deploy AKS Periscope (before the issues occurred).
AKS Periscope Overview
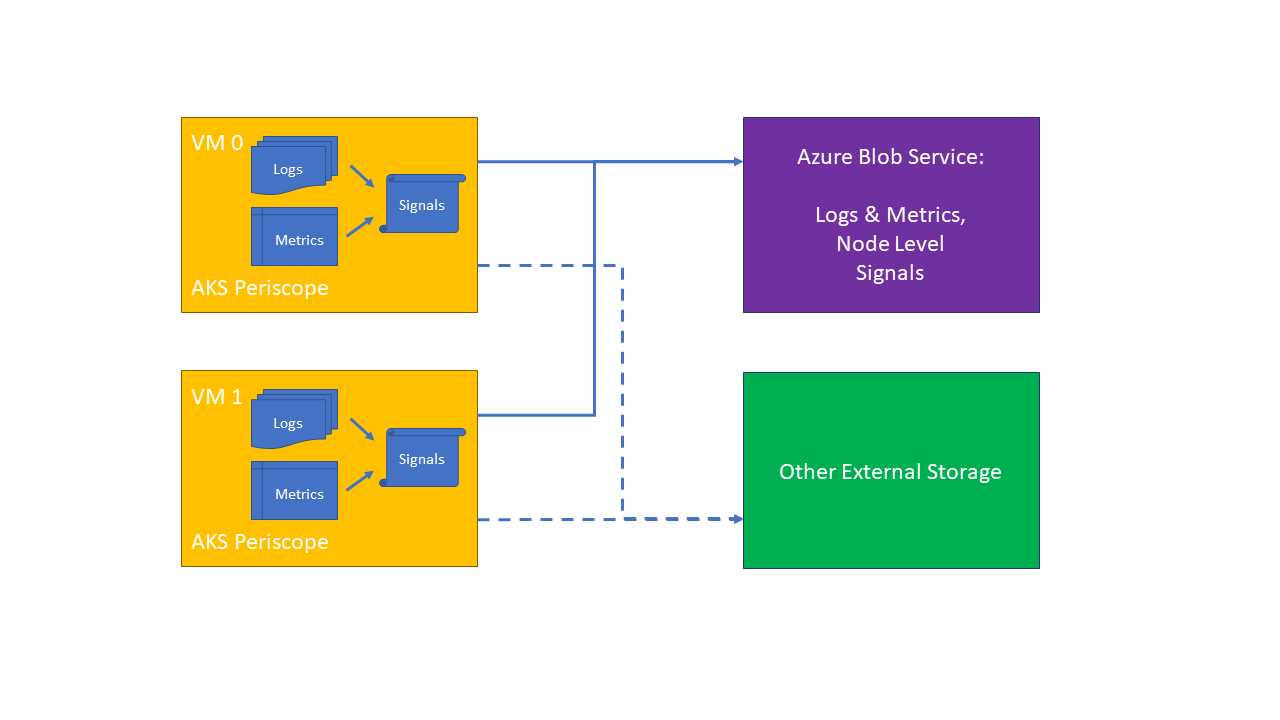
AKS Periscope deploys a daemonset into your cluster which will collect useful logs from each node, including:
- Container logs
- Docker and Kubelet system service logs.
- All node level logs
- VM and Kubernetes cluster level DNS settings.
- Describe Kubernetes objects
- System performance (kubectl top nodes and kubectl top pods).
Excerpt from the AKS Periscope repo:
Hopefully most of the time, your AKS cluster is running happily and healthy. However, when > things do go wrong, AKS customers need a tool to help them diagnose and collect the logs necessary to troubleshoot > the issue. It can be difficult to collect the appropriate node and pod logs to figure what’s wrong, how to fix > the problem, or even to pass on those logs to others to help.
AKS Periscope allows AKS customers to run initial diagnostics and collect and export the > logs (such as into an Azure Blob storage account) to help them analyze and identify potential problems or easily > share the information to support to help with the troubleshooting process with a simple
az aks kollectcommand. > These cluster issues are often caused by incorrect cluster configuration, such as networking or permission issues. > This tool will allow AKS customers to run initial diagnostics and collect logs and custom analyses that helps them > identify the underlying problems.
AKS Periscope Deployment Considerations
I had issues using the az aks kollect deployment method, so opted for the Kustomize Deployment
method, as this offered full customisation and greater control.
One additional requirement I had was for the AKS Periscope pods to run on system nodepools that had the CriticalAddonsOnly=true:NoSchedule taint applied. By default, they wouldn’t start on the system nodepools, so I had to add a toleration to the Kustomize definition (shown below).
AKS Periscope Deployment Script
The deploy_aks_periscope.sh script will do the following:
- Create a SAS token valid for 60 minutes.
- Deploy AKS Periscope into your cluster.
- Collect and save logs into the storage account specified (this collection only runs once).
AKS Periscope Update Script
As the log collection only runs once, you will need to update DIAGNOSTIC_RUN_ID to trigger subsequent log collections.
The update_aks_periscope.sh script will do the following:
- Create a SAS token valid for 60 minutes.
- Update the
azureblob-secret. - Trigger new log collection.
- Collect and save logs into the storage account specified.